April 2022 - April 2022
An application designed for the extraction of search results from various search engines and subsequent exportation to a CSV file, featuring a sorting mechanism based on relevance.
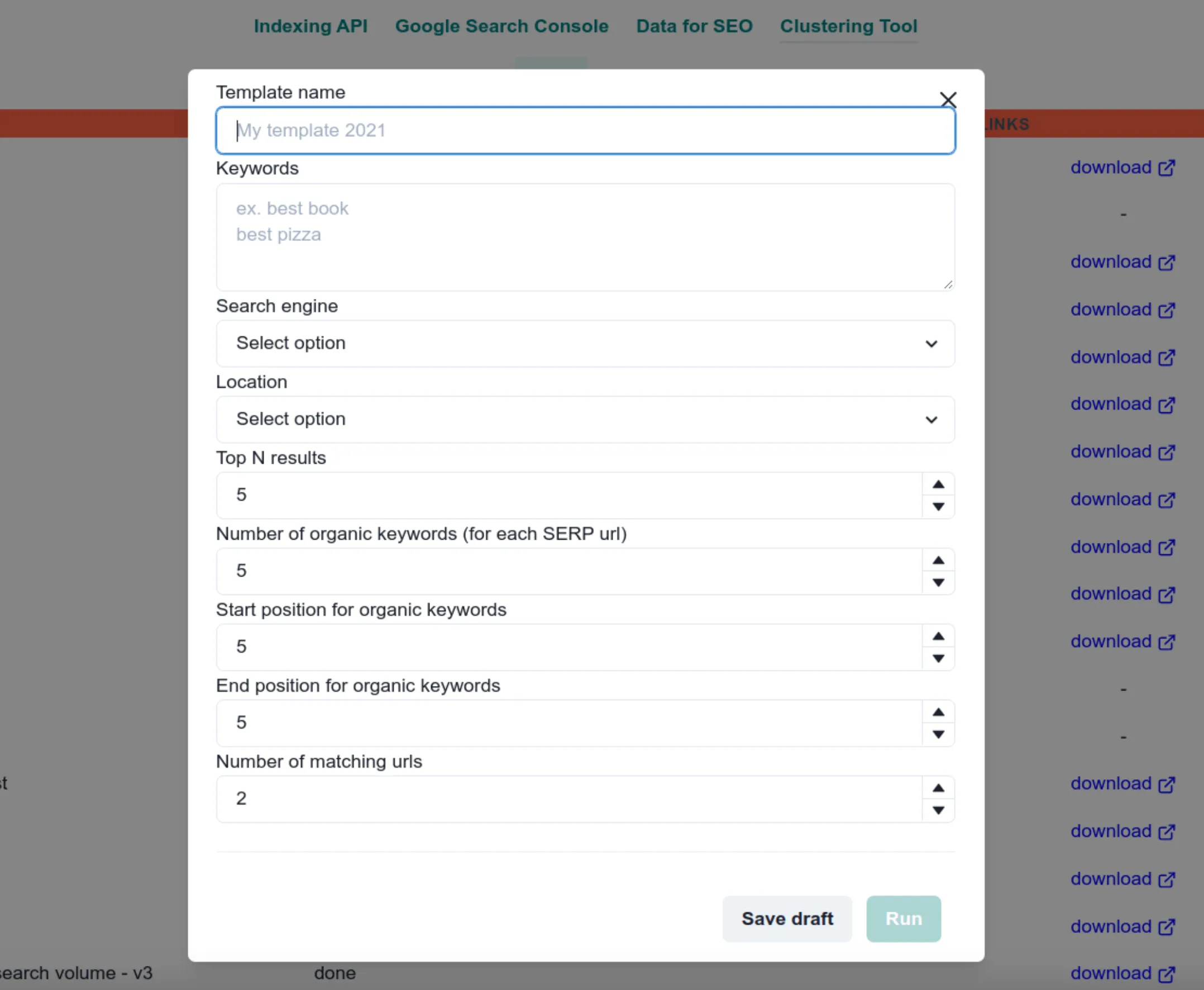
Project Goal
The client possessed a list of keywords and expressed the need to determine the ranking of their website for each keyword, as well as the rankings of their competitors.
Given the large volume of keywords, the client sought automation for this process.
Initially, a Python script was used for this purpose, requiring manual execution.
I improved the workflow by developing a contemporary application that automated the entire process, streamlining all necessary tasks.
Solution
React
React was employed for the user interface (UI) development.
In keeping with the client's satisfaction with the UI from the previous iteration, I retained its design.
Additionally, the choice of React was motivated by its inherent reusability, which facilitated the creation of a component for the search results that could be easily reused throughout the application.
NodeJS
Node.js was implemented for the backend infrastructure.
The rationale behind this choice stemmed from the absence of an API in the previous version, which relied on a Python script requiring manual execution for file processing.
In an effort to automate this process, I introduced a Node.js server that handled file processing automatically. Additionally, this decision ensured language consistency between the frontend and backend, promoting code uniformity.
TypeScript
The prior iteration was constructed with vanilla JavaScript, presenting challenges in terms of maintainability.
To address this, I opted for TypeScript, leveraging its robust type safety features.
This choice not only improved code maintainability but also provided the flexibility to undertake refactoring efforts with ease when required.
MySQL
The decision to opt for MySQL the database solution was made with careful consideration, taking into account its extensive popularity and its ability to effectively store and manage reusable crawling templates.
This choice aligned seamlessly with the project's requirements, ensuring robust data storage and retrieval capabilities while enhancing scalability and maintainability.